Searching inside datasets
This post was written by Robin Gower of Swirrl about our work on the Integrated Data Programme.
How can we help users to find the right data?
This was the seemingly simple question posed to us by the Department for International Trade.
Trade data is deceptively complex. There are several datasets that seem to promise the same thing — information on trade flows — published by both ONS and HMRC. Deciding which dataset to use in a given context turns out to be a hard question to answer for the uninitiated, requiring people to learn more about technical product classifications than they might care to! Finding data is non-trivial.
Our User Research helped shape this problem with the help of a “trade data finder” persona:
I know how to interpret and analyse data, but not where to find trade data, or how to choose between the sources, and complex dataset methodology doesn’t help
We also identified a representative research question:
How many cars do we import from Germany?
Easy to ask, difficult to answer.
Finding data from metadata
As a benchmark, let’s try searching for this on the ONS Website. We’ll search using the keywords “cars import Germany”.
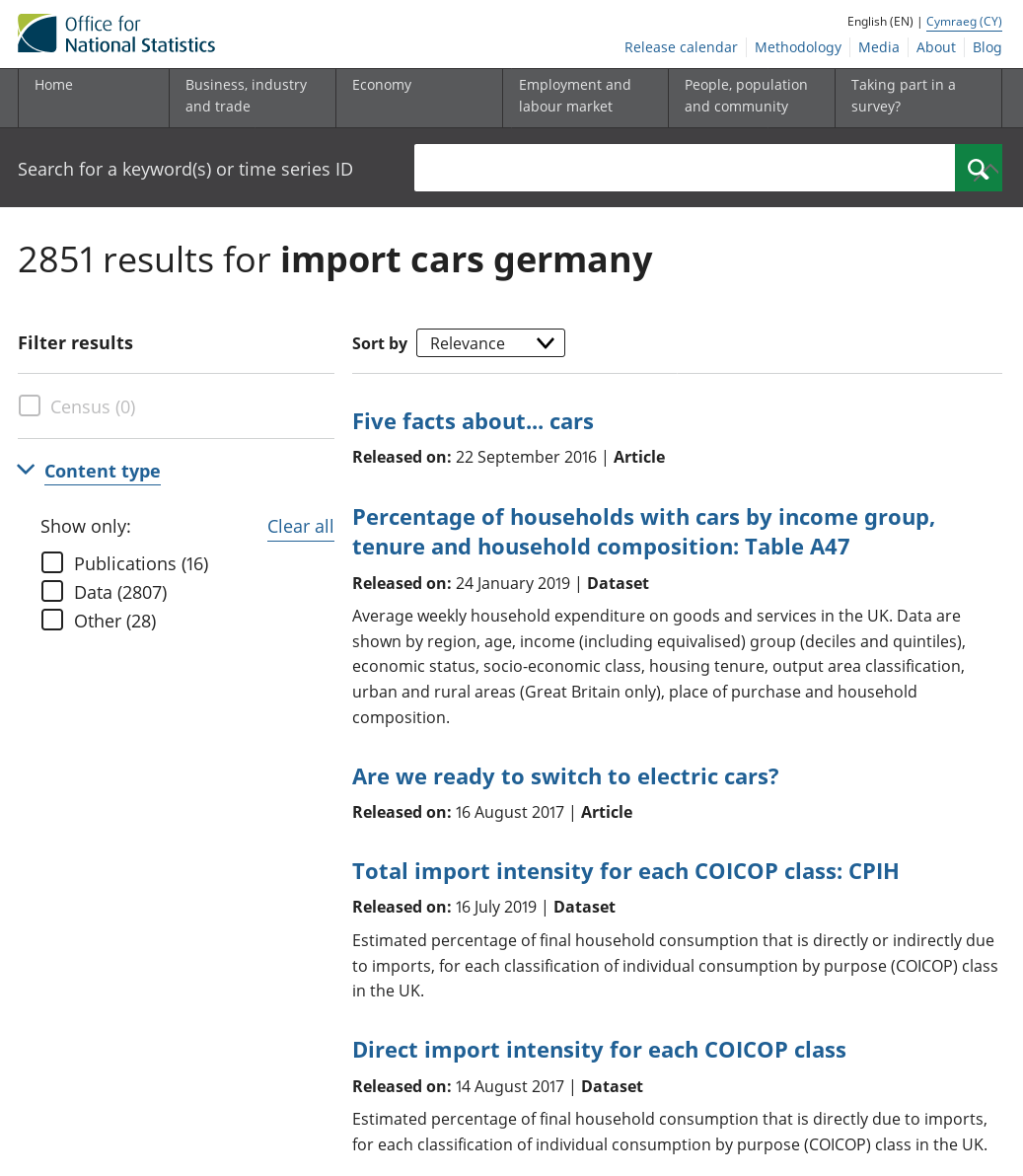
ONS Beta Search
We receive a few results about “cars” and a couple about “imports”, nothing obviously about “imports of cars” (i.e. covering both terms at once) and no mention at all of “Germany”.
Why is this?
Data search tends to work by searching over datasets. The data is packaged-up at a certain level and the search operates over those packages. The contents of those packages is summarised with a title and a comment. This provides a metadata description of the data inside.
The problem is that this package-level metadata is necessarily a summary, and doesn’t include all of the keywords that are present in the contents. If the dataset’s title or summary don’t include the keyword, then it can’t be matched. If the keyword appears in the data but not the metadata we’ll never find the dataset.
It’s instructive to look at how the retired ONS search engine handled this query.
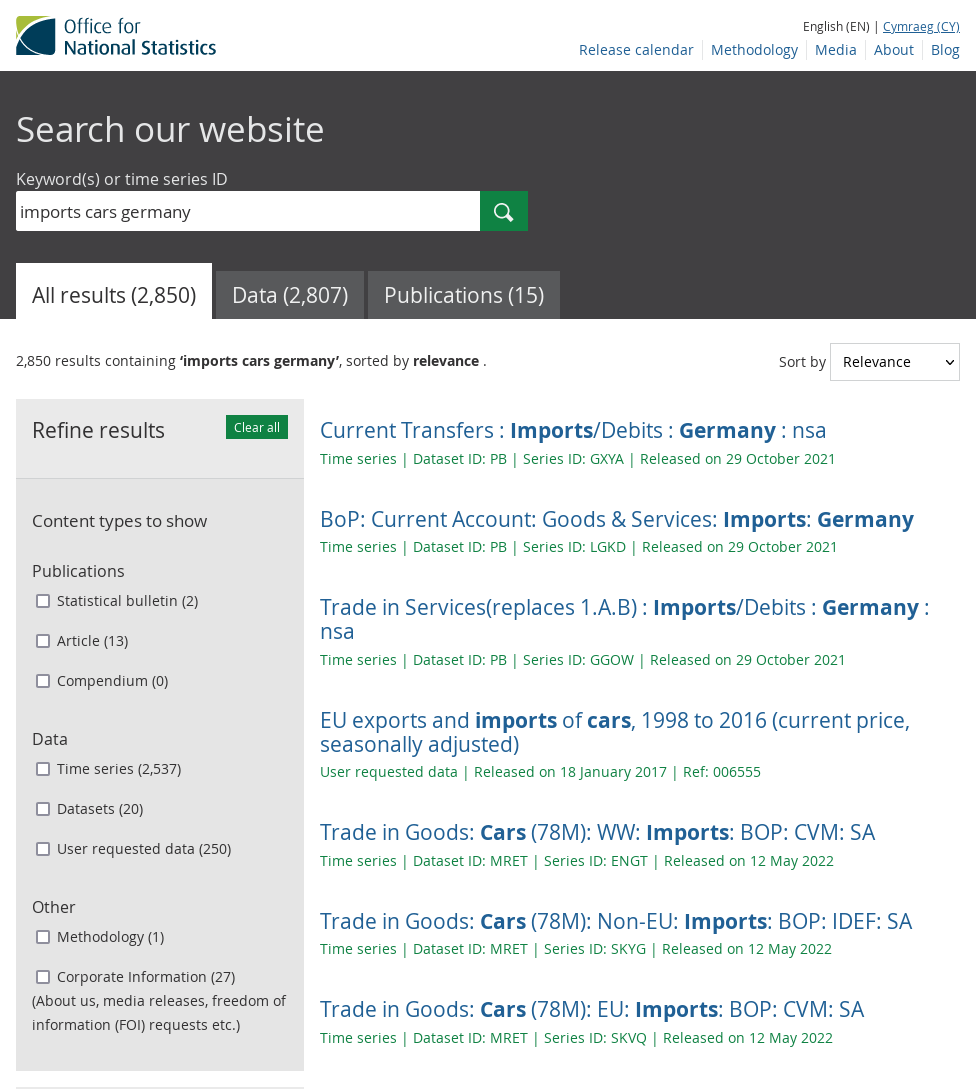
ONS search
Whereas the previous results were articles and datasets, now we’re seeing lots of time series. These are slices through a dataset holding several dimensions constant while time varies. The time series metadata tells us what dimension-values are held constant in each case.
The more granular packaging (at time series level) means more of the things referred to by the data itself are brought up to the metadata level. Now we’re able to match on “Germany” and we’re also seeing results which match more than one keyword.
Finding data from data itself
What if we were to continue this vein? What if we were to index the contents of the dataset – and all the terms it uses to describe itself? Would that help users to find the right data?
Well this is what we’ve done and we think it does help!
We’ve built a structural search prototype which extends the principle to its logical conclusion. We’ve indexed all the classifications and statistical observations directly. We are searching data, not metadata.
Our searches can match deep inside datasets for things that weren’t mentioned in the package-level metadata. Indeed these are things that can’t reasonably be included if the metadata is to be any shorter than the full data.
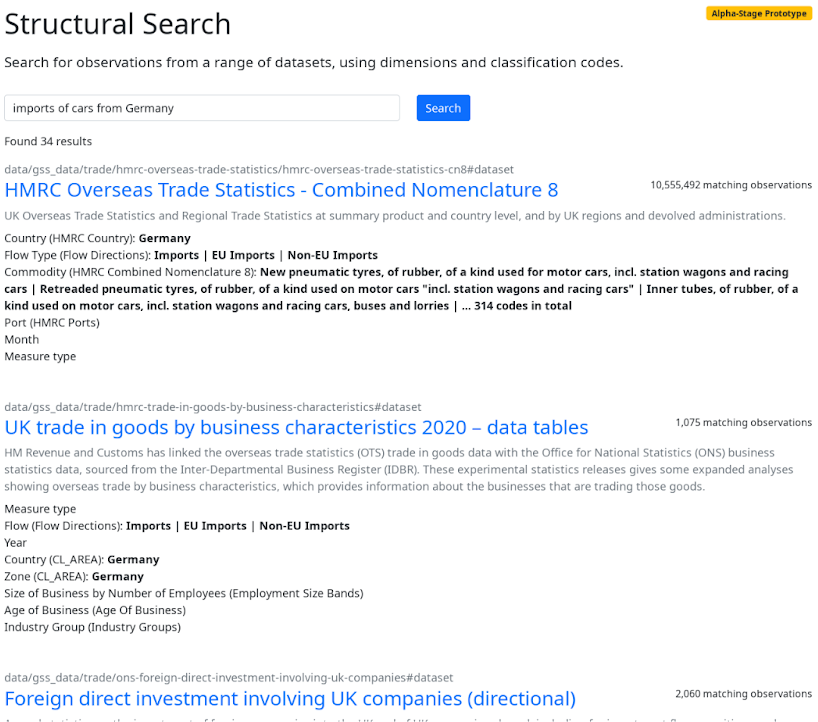
Structured search alpha
Here we’re matching datasets that can answer our query and showing the dimensions and classifications that are available.
By indexing the data in this way we can also use knowledge of it’s structure to help prioritise the results. Other things being equal, a dataset that matches on a broader range of dimensions probably has more information relevant to your query. That’s what we’re doing here.
Indexing data cubes
We’re able to offer a search interface like this because of the work we’ve done to extract the data from each dataset into a consistent format.
The Integrated Data Programme – Dissemination service has adopted the RDF Data Cube standard as a basis for this consistent format.
We’ve transformed 100’s of datasets from across Government (not just the ONS) covering more than 50m observations into linked-data meeting this and several other data standards.
This means we have rich descriptions of the observations, each linking to many statistical classifications which in turn are described in the knowledge graph.
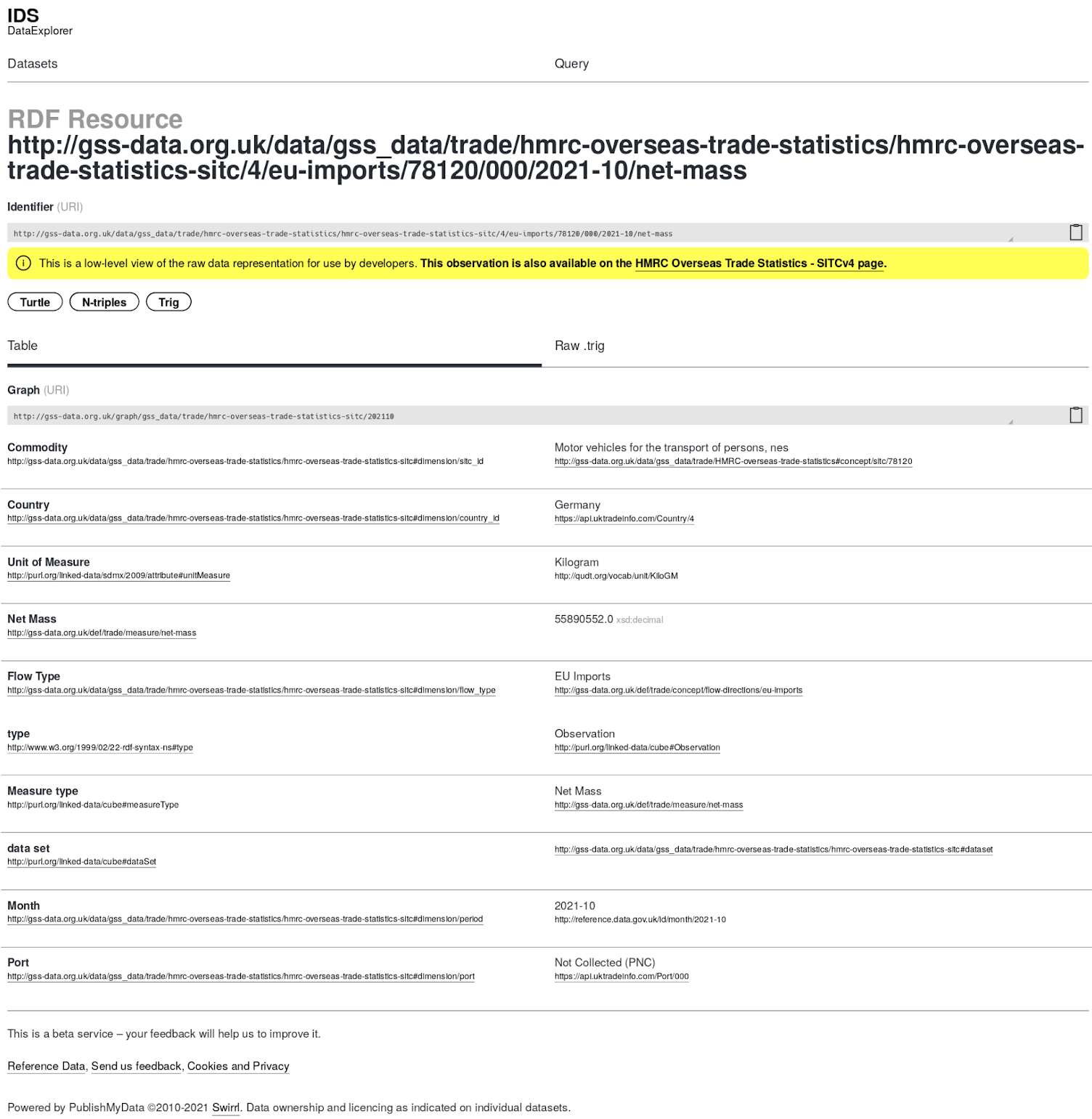
It’s this granularity of description that makes structural search possible.
You can explore the prototype at search-prototype.gss-data.org.uk. We’d love to hear what you think.