End to end alpha
This is a post about our ongoing data discovery project
As a recap, this service is about allowing our users to do 3 things
We want to:
- enable users to find data easily
- enable users to customise datasets
- enable users to browse by location
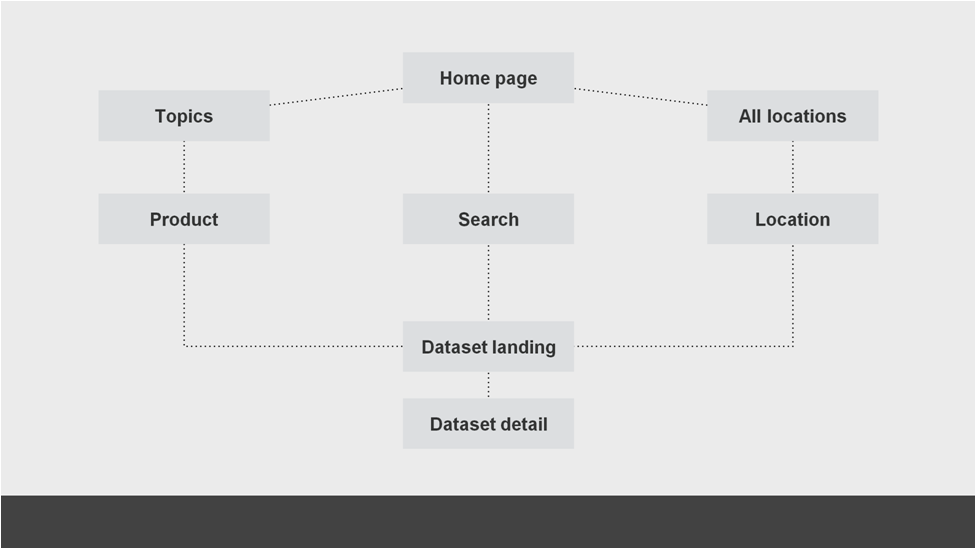
To do this we have been speaking to our users to understand more about how the engage with the ONS online. We know from our analytics that 70% of users will come to the site via an external organic search (for example, they “Google it”). The motivation for why they have searched varies a lot. Sometimes they will reach a dataset page (a low-level page within our site structure) directly from a search and so will be able to move directly to selecting the information they want. Other times they will arrive into different parts of the site and we need to do a better job of guiding to them to the area they are looking for. At a very simple level, a process that looks a little like this:

To explore this with our users we have been looking at a variety of options that could exist within the site to guide them to the content they are looking for. We have done this via a series of mock-ups, very proto prototypes and wherever possible, real code.
As ever, user research is a fascinating process and this, the process and cross-referencing with our analytics has taught us some really important things.
- Some users like our current websites
- Analytics suggests people search by city
- Recruiting users for research is hard
- Wording and labels are really important
- Users need supporting information for context
- ZIP folders can cause problems
- Geography is hard
- Nested lists are probably the most complex pattern
- Users want to “search first”
- We should respond to the user within one second
- “Users find some spreadsheets difficult to navigate”
Some users expect locations to be ordered alphabetically
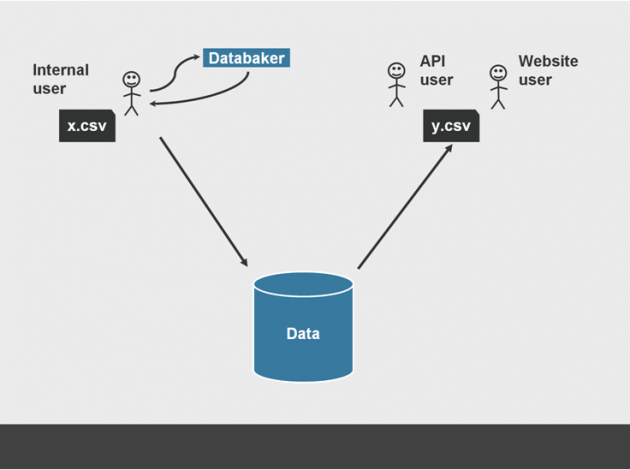
To try and meet these user needs we have been creating a first cut of the technical systems that are required to underpin it.
For this service, that means a minimum viable product (MVP) internal tool to upload a excel file that has been processed by databaker, a collection of message queues and the wonderfully titled CVS chopper to break the excel file down into rows and pop them into a database. Once they are there, they can be used to drive a front-end interface that allows users to navigate data as a collection of individual interactions and get back just the information they want as a tidy CSV file.
A single paragraph, but weeks’ worth of work that can perhaps been summarised even more clearly as this process:
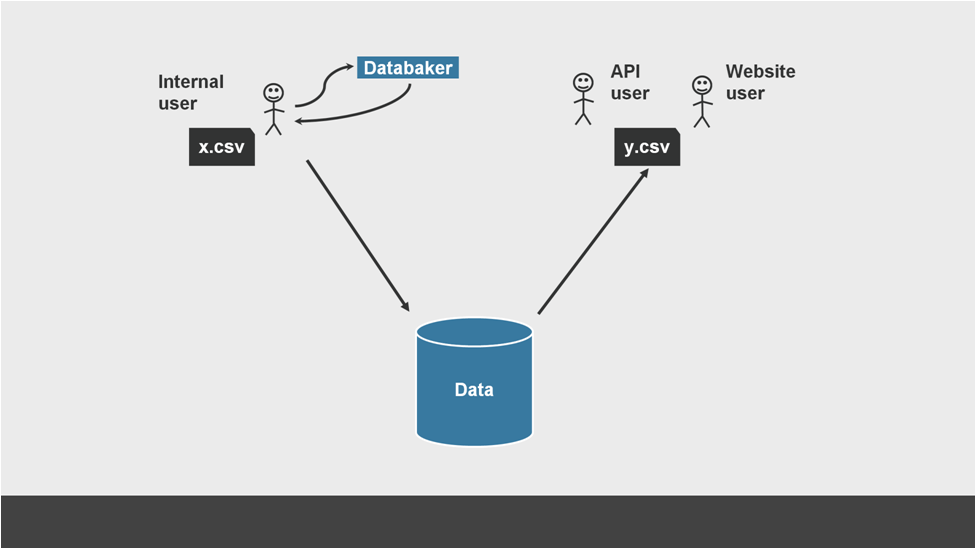
Show the thing?
As with the rest of this project, the latest version of our prototypes and research can always be found on our Github page.
Our next steps are to make this a little more robust (and only the bare minimum of that) so that we can start to make end-to-end journeys using real data available for a lot more people to work through. We will post more about this as it happens, but as a spoiler, we are going to be requesting more people try out what we have built so far so that we can ensure that we continue to iterate it in line with what our users need. Please do get in touch if you would like to be one of those people.