Presenting data in context
I recently introduce a number of principles that could guide how (open) data is published by the ONS. The fourth principle was: “Always present data in context”.
This principle reflects that statistical data is often accompanied by a certain amount of supporting information. For example, describing how it has been collected, and to identify any known issues with its quality. The context helps ensure informed reuse of the data.
The fifth principle, “Make datasets legible”, has a similar goal, but focuses on the internal details of the dataset. For example the dimensions and code lists that are used to help report observations.
On the ONS website, presenting data in context means ensuring that datasets are linked to the relevant material. All of that documentation, for example, on methodologies, needs to be published to the web, allowing it to be easily referenced and shared with others.
When you’re viewing and interacting with data on the ONS website that context should be at most a few clicks away, but what about when data leaves the website? How is the link between the data and the supporting documentation preserved?
Data leaves the ONS website not just when it’s downloaded by a user but also when it’s mirrored and archived by other systems. How do we help ensure that data is presented in context in those situations?
Some data and file formats make it easy to include additional context and links. Structured formats like JSON and XML can include metadata. Formats like Excel and OpenOffice can include human-readable documentation, often in the form of additional worksheets, but formats like CSV files don’t support this kind of extra information.
One option would be to always deliver packages of data, for example, a zip file that might include not just the data file(s), but also the relevant human and machine-readable supplementary information.
Some data portals do this already. The UK data archive provides structured packages of data that also includes supporting documentation.
But packaging data into zip files can create friction for users. User testing on the data discovery alpha has shown that in many cases users just want a CSV or Excel file that they can immediately open. They don’t want the extra overhead of having to unpack the data before diving in.
This highlights the need to make context accessible not just on the dataset pages, but also at the point that a user has downloaded their data, allowing them to quickly access it when it’s needed.
But there may be cases where a package might be preferable. A single download might be better when there are several data files that make up a dataset. Or if the user wants access to documentation whilst offline.
Bundling documentation with the data might also be helpful if users are collecting multiple datasets for a later analysis. It saves them having to bookmark or otherwise find the documentation they need.
If data is being archived or mirrored to other websites, it may be useful to also package the data with metadata that provides links to the supporting documentation.
To test the waters I asked people on twitter what they would expect to see in this type of data package:
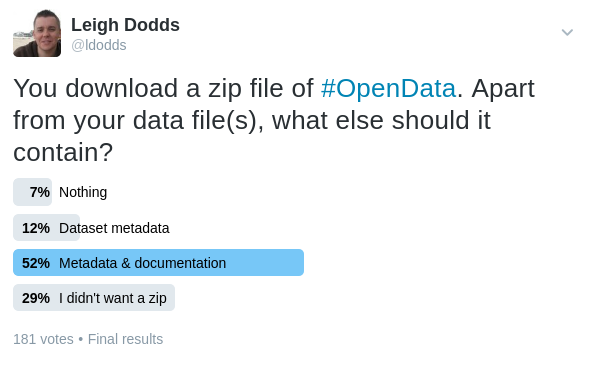
The fact that 29% of people didn’t want a zip in the first place confirms the existing user test results. Discussion suggests that users wanted to quickly script up data downloads, or just expected to lookup documentation online.
But 64% of respondents seemed to welcome a data package and wanted it to include some additional context. This suggests that at least some users would welcome the ability to grab everything in one go. This is something that it may be useful to test further during the data discovery project.
In the meantime, if you have opinions or feedback, then please get in touch. Do you prefer simple file downloads or are there cases where a package of data and content is a better option for you?
Also keep an eye out for opportunities to get involved with user testing and surveys by following @ONSDigital.