Technicalities of the eQ Alpha – Outcomes – Part 3
This post is a technical dive into the eQ Alpha; the technologies and approaches we used and some of the thinking and lessons we learnt.
Introduction
For a quick refresher on what the eQ is all about see my introduction to the Discovery and Alpha and summary post, which includes a video of the final system we produced.
I haven’t gone into the details of specific requirements we need to satisfy with the eQ before, other than mentioning that the system will cover Business and Social surveys as well as the Census. I think it will be useful to provide a bit more detail on the Census part of that scope now in order to explain some of the technical decisions made in the Alpha.
In terms of architecture, the Census poses the most challenging requirements. This is a survey that goes to every household in the UK over a 6-week period, which introduces some interesting scalability needs (some basic modelling places it at half-a-million or more peak simultaneous users on specific days over that period), for this period the system needs to be very resilient. This isn’t to say that system shouldn’t be scalable and resilient in any case, but it certainly emphasises the point.
Firstly, to be clear, we never set out to try and meet those kinds of scalability numbers in the Alpha or solve all the issues this introduces. What we wanted to prove was the fundamental approach we would be taking would scale horizontally (i.e. doubling the number of servers would roughly double the supported users); as opposed to requiring vertical scaling (adding more CPU/RAM/Storage to servers) which only gets you so far before reaching physical limitations and quickly becomes very expensive. We also wanted to prove that the approach would help facilitate (and not prevent) a high resilience setup.
I should also mention that developing the eQ as an independent product with a dedicated team is part of the wider ONS technology strategy to move to a product and services based approach. It should go without saying, this also means we want clean segregation of products and services with well defined scope and interfaces, this all feeds into the approach to the Alpha and how we divided the system up.
Approach
Keeping the requirements in mind and building on good engineering practices, one of the key decisions at the start of the Alpha was to work to the 12 factor apps methodology. This was to ensure we could deploy to modern cloud platforms, enable continuous deployment, scale up easily and offer maximum portability. Even within the timescales of the Alpha this proved to be a valuable approach to have taken as we switched providers a few times, setup automated deployments and also validated the scalability of the architecture via load testing, I’ll provide more details about these elements below.
The eQ team were given the often rare opportunity to work on a greenfield system, and this wasn’t a privilege that was taken lightly. As I wrote previously about Sprint 0, we wanted to push for a high level of continuous delivery maturity, whilst keeping the investment proportional to the scope of an Alpha (prototype, non-production, rapid development). We also took into consideration the desire to explore the tools and techniques that we would be using in Beta when producing the production ready system.
We used Travis CI to manage our continuous integration, you can read more about this in my post about the team toolkit. Travis worked really well in Alpha and we plan to use it in Beta for continuous builds, although we will be introducing our own Jenkins server as well to handle the more sensitive aspects of our production deployment pipeline.
Architecture
The Alpha system was composed of two main components, the internal facing (to ONS staff) authoring experience (eq-author) and the external facing (to the public) respondent system (eq-survey-runner). It was decided both of these would be web apps, the respondent system should obviously be so, but the authoring could have been developed as a desktop application. However, there are a lot of advantage of zero-footprint apps (software as a service), such as simple client deployment (i.e. none required other than the browser), updating (you always get the latest version), cross-platform (should work on any modern browser/OS).
The diagram below shows the architecture we concluded the Alpha with:
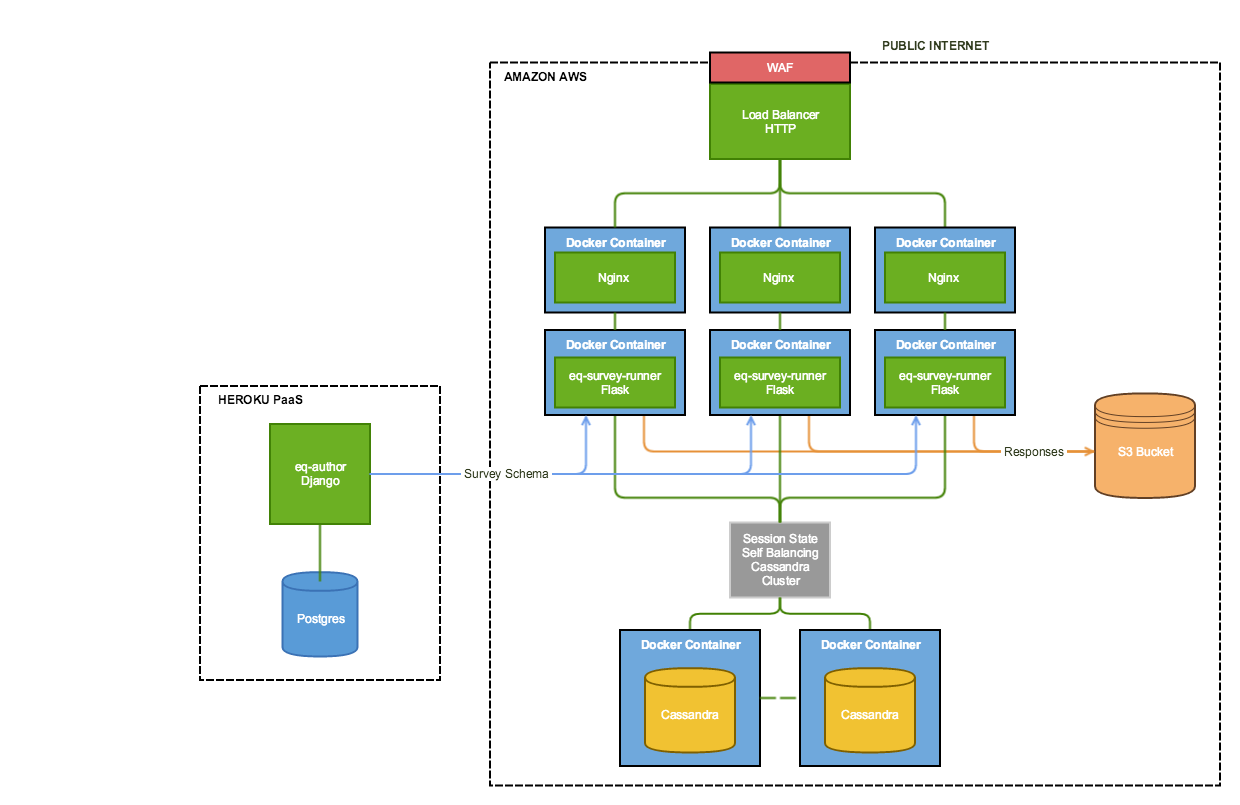
eQ Alpha Final Architecture
Authoring (Internal)
The authoring tool (eq-author) allowed internal staff to login and setup surveys, each of which could contain multiple questionnaires. The questionnaires could be edited in an authoring experience allowing them to add sections and different types of questions, set validation and routing/navigation rules. As this is for internal users, we are able to target modern browsers (e.g. ONS desktop standard is IE11 and Chrome).
This was a Python based web app built using the Django framework, which was selected as it includes a number of capabilities out the box we knew would benefit from, such as a UI template language, user account management, automated database schema migration and a built-in admin dashboard. It is a well established mature framework for the kind of app we were developing. The authoring tool was deployed to Heroku‘s Platform as a Service (PaaS), connected to a Postgres database as a service.
The requirements of the author system database were fairly minimal in Alpha and wouldn’t need any special capabilities, Postgres is well supported by Django, open source and came out the box with Heroku. It was the obvious choice. Django’s database modelling also abstracts the database to the point that it wouldn’t be much effort to switch to an alternative, it also handles database schema migrations automatically, which removes one of the usual areas of pain, although you do need to embrace Django’s approach to databases to get these benefits.
Performance (e.g. server roundtrips) can be a concern when running web-apps vs. desktop software, this is something we considered in the approach to the Alpha. To provide responsive performance, and the rich types of interaction we wanted to get when designing a questionnaire, the authoring experience was developed as a one-page app using AngularJS. This minimised the need for roundtrips to the server, other then background saving of changes to the author’s questionnaire.
Angular did enable rapid development as it puts a framework in place that makes a lot of decisions for you and allows you to get straight to work on the interesting stuff that adds value (rather than boilerplate code). However, we did find Angular quite prescriptive in its approach and throughout the duration of the Alpha felt increasingly dependent on and constrained by it (we’re not the only ones). By the end of the Alpha we were investigating alternative frameworks and libraries that would offer the flexibility we wanted with less constraints and prescription, we prototyped a few of the Alpha concepts in ReactJS with Redux and after reviewing the pros and cons, we have decided to make the switch to this combination for Beta.
Respondent (External)
This app (eq-survey-runner) needed to do one thing and do it well, execute and render surveys designed in the author app, it needed to be performant and scalable as well as targeting a wide variety of devices, browsers (and versions), screen sizes, language and accessibility needs.
As with the eq-author, this was a Python app, but we chose to use the Flask micro-framework instead of Django. We simply didn’t need all the extras that a framework like Django provides out of the box. In front of the Flask app we deployed NGINX which is a high performance web server and reverse proxy, Flask shouldn’t be deployed as its own web server (it has the capability, but only for development/debug work).
In order to cater for the huge variety of possible users (social, business and Census) we developed the Alpha respondent system using progressive enhancement, ensuring that even with no JavaScript or CSS it was still functional (albeit basic and not very pretty). One element that played well into this was one of the few things that is bundled with Flask, the Jinja2 template engine, which gives good flexibility in the backend, including template inheritance. This allowed the base functionality to be handled in the backend in a clean way.
To support a responsive frontend we chose to use the Zurb Foundation responsive framework, which was great for prototyping in the Alpha, but very generic, so in Beta we’re planning to create our own pattern library specific to our needs.
At the start of the Alpha the respondent system was also deployed to Heroku, just like the eq-author, but early in the Alpha we switched to Amazon AWS in order to explore and test capabilities around Docker for build/release and the use of a Cassandra cluster for load balanced sessions state storage (maintaining in-progress survey responses). We made use of an AWS Web Application Firewall (WAF) and Elastic Load Balancer (ELB) to route traffic to the survey runners (via NGINX).
We chose Cassandra as it is open-source, has a Python driver, is mature and used by many systems, offers high availability, proven scalability and fault tolerance, specifically it is also proven to work across multiple data centres and regions, which keeping in mind our Census requirements, would support the types of high resilience needed. Cassandra worked pretty well after it was up and running, although we weren’t really stressing it in the Alpha or doing anything fancy other than storing some key/value pairs (with some JSON data). Performing load testing did reveal some issues in the way we were connecting to it from Python around connection pooling and management, which we resolved.
Load Testing
In the Alpha we made use of Flood.io, a cloud based load testing service (running JMeter) to test the respondent system, performing automated completion of an example multi-section survey. We wanted to prove that the architecture would scale horizontally (as mentioned previously). I’m pleased to say that we got the results we were expecting, moving from one to two instances running just short of doubled the number of requests per minute the system could handle, introducing a third instance equally provided close to 3x the original capacity.
The actual load numbers here (requests/minute etc.) aren’t that important as we didn’t undertake any detailed modelling of user behaviour, performance profiling of the application, servers or optimisation in the Alpha and just scaled out the system we had as-is, the important outcome was that the test validated the horizontal scalability of the system sufficiently for an Alpha prototype. It was also good to weed out some minor issues (such as the Cassandra connection pooling mentioned before) and get a feel for whether we had any major bottlenecks (nothing jumped out at us during testing).
Now we have confidence in our general approach, we’ll be spending more time on modelling, performance, load testing and optimisation in the Beta, we’re also considering establishing automated performance testing as part of our continuous delivery pipeline.
Docker
Docker caused a fair amount of pain in the Alpha, especially around composition and linking of multiple dependent containers. We were using Docker compose but hit problems with differences between running on Mac and Linux and in AWS, we also found that performing ‘clean’ builds with Docker can really slow things down, having to re-download many large images and file system layers, compared to working without Docker. We lost a fair amount of time dealing with issues and learning/debugging it, we kept saying ‘it shouldn’t cause this much pain or be this difficult to work with!’ but really it was for one reason or another, perhaps it is the documentation and relative newness of the technology (we actually upgraded the day a new version came out in the Alpha as it fixed some known issues we were experiencing). Ultimately we didn’t really get many benefits from Docker in the Alpha, mostly because all our builds and infrastructure was automated already, and lost a fair amount of time to it. At this point we’ve decided not to use Docker in the Beta, we could revisit it later if significant value is identified is using it, but our preference for PaaS (see below) probably negates this.
PaaS
Using a PaaS greatly simplified the management of our infrastructure, actually it meant we didn’t need to manage much at all, Heroku allows you to ‘git push’ your code (assuming you’re using a supported technology/framework) to their service and get a running instance returned in minutes with a URL, including the backed services (Postgres in our case). This was perfect for getting the Alpha up and running quickly and minimising the effort required to manage the system.
Utilising PaaS can simplify access to backed services (like databases, messaging, logging and metrics), offer built-in scaling and resilience and generally remove a lot of friction and overheads associated with managing your own infrastructure. This doesn’t come as a surprise, GDS are establishing a cross-government PaaS offering based on Cloud Foundry and the ONS technology strategy is aligned with this move, with Cloud Foundry due to be setup internally as well. We are working with GDS on this and managed to port the entire eQ Alpha to the GDS PaaS test system at the end of the Alpha (we did have to swap Cassandra for Redis), it was pretty easy and this really proved the value of working to the 12-factor app methodology.
Given this strategic direction and the benefits of a PaaS approach we’re planning to make more use of it in Beta, possibly running the whole system this way if we can.
Infrastructure Orchestration
Part of targeting a mature continuous delivery model involved scripting our infrastructure. We used Terraform to orchestrate the deployment of the entire system. Terraform allows infrastructure to be described in config files, representing resources across multiple providers (in our case Heroku and Amazon AWS) and then creates that infrastructure automatically, it can also apply any changes to the config by identifying the differences and pushing those changes to the provider. This meant no manual steps in bringing up and deploying an environment, anyone on the team could deploy the whole system autonomously. This included generating new DNS entries in AWS Route53 for the new environments and linking everything together, this really did make it simple to create and deploy environments.
One minor pain point we hit in Alpha was sharing and owning the state file produced by Terraform, essentially the person who created the environment has the state file associated with it and is the only person who can make changes to it. After some digging we found that the remote config capability allowed for state files to be stored in various backends (such as an AWS S3 bucket) for sharing, we used this in combination with Travis CI to maintain a nightly build environment.
Of course the disadvantage of creating environments so easily being that at one point we had 8 separate environments deployed in parallel for one reason or another and the associated costs of running them all!
Python
I wanted to say something about the use of Python and its introduction as I feel there are some interesting outcomes from the Alpha in this area. As mentioned previously, the team chose to use Python for the backend development on both sides of the system. Testament to the ease of learning a language like Python, only one of the four developers on the team had used it before but by the end of the Alpha, the whole team was comfortable developing in it. This doesn’t mean everyone is an expert, but a significant amount of software development experience is transferrable between languages, such as writing clean code with strong design principles and being pragmatic.
Speaking with the developers, just over the course of the Alpha, they’re saying they prefer developing in Python to the languages they’re much more experienced in (such as Java and PHP) and have found it to be very productive and powerful. I don’t believe this to be specific to Python, I’m sure going with Ruby would have had the same outcome, possibly other languages too but it is an interesting outcome to think about.
And that’s all for part 3…
One comment on “Technicalities of the eQ Alpha – Outcomes – Part 3”
Comments are closed.