Journey to the centre of the dataverse, chapter 3
In Jules Verne’s Journey to the Centre of the Earth, Axel and Professor Lidenbrock finish their preparation and complete their initial overground travel to Iceland. Once in Iceland, they start their journey by descending into the earth through a volcanic crater. The crater is one of three on an Icelandic volcano, indicated by a shadow defined in the coded instructions.
In our journey to the centre of the dataverse we’ve completed our preparations and initial travels. We have now started our descent into the dataverse.
You could even say that we started by choosing one of three database options: relational, non-relational, or graph. We would like to emphasise to taxpayers that our choice was slightly more evidence led than waiting around for a sunny day in Wales to see where shadows were cast.
Real live bleeding fingers and broken code strings
Our show and tell for chapter 3 included the first live code demo of two back-end services interacting with each other. Watching live code running underlined that we had well and truly started on the descent into the dataverse. It wasn’t all perfect but we think that’s what show and tells should be like.
(We’ve been talking about the steps that we have to take to reach Public Beta and discussing Reid Hoffman’s aphorism “if you are not embarrassed by the first version of your product, you’ve launched too late”. I’d like to propose an additional version: “if there isn’t more than one person holding their breath during a technical demo in a show and tell, then you’ve waited too long to demo it.”)
The demo included the Import API updating a message queue. An important part of this chapter was the creation of specifications for this and for several other key APIs (import, dataset, filter, codelist) that will underpin our dataverse. We also got our graph database successfully into Amazon Web Services.
Hide N’ Seekin
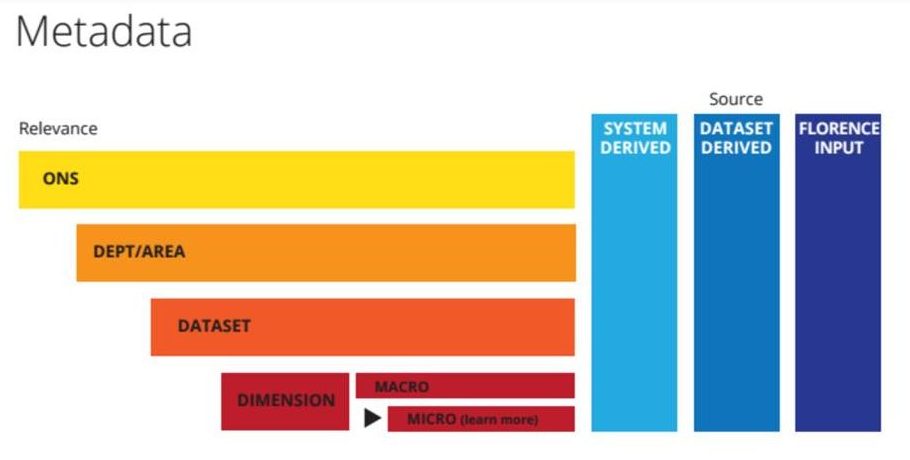
We’ve talked in previous chapters about metadata and how important this will be in allowing users to find data. Hunting and capturing metadata is likely to be a regular occurrence in this narrative.
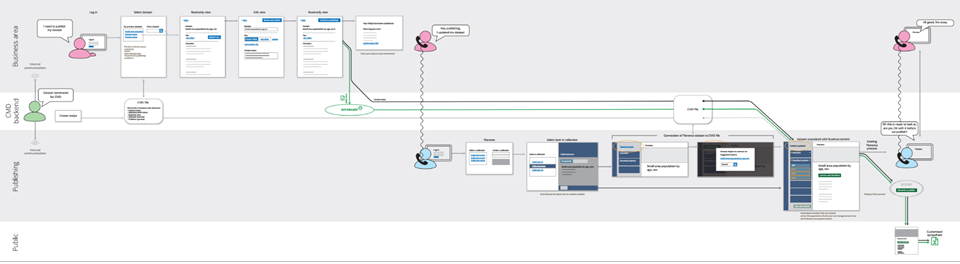
In this chapter, we did some more work on where this metadata will appear in the user journey [PDF link]. In the PDF, you’ll see that we’ve looked at what different metadata will refer to. We’ve also looked at whether the metadata will come from the system, the dataset, or be manually entered into our CMS (also known as “Florence”).
We’ve talked before about how important our internal users will be to the success of this project. In this chapter, we mapped out an end to end version of what the upload process could look like for them. This allows for both manual upload of data and metadata into the Customise My Data system and for the longer-term objective of taking this metadata and data automatically from the internal business systems that store ONS data and metadata. At the same time, we did some more work on what the user interface could look like for an internal user (select the “sign in” button to move past the first screen).

Can’t hardly wait
Now that we’ve got past the preparation and started our journey into the dataverse, we’re keen to explore further. So keen, in fact, that the production of these notes was slightly delayed. Return soon for the next chapter of our adventures in the dataverse.
Please note, unlike Axel and Professor Lidenbrock, who nearly died when they ran out of water, we’re lucky enough to have catering taken care of by our multi-talented service manager.