Sprint notes – Beta – Sprint 6
After a quick break for the summer, here is an update on the progress on the current Customise My Data Beta project. As a reminder, this is a project to use the ONS website to allow users to find data more easily, break down data into small chunks and to add geography as an additional view on our data.
A work flow that might looks something like this:
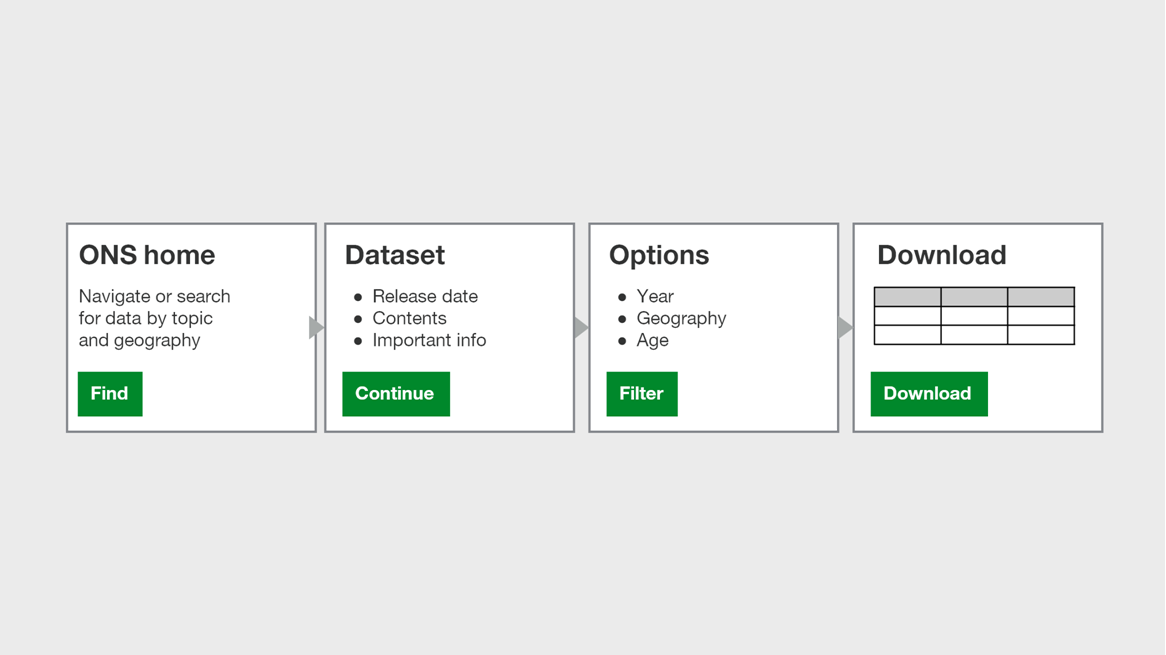
The work is being undertaken by three agile teams, focused on different bits of the project and technologies.
As ever – everything we do is available to have a look at on our prototype pages.
In Sprint 6 the teams were focusing on the core interactions with data. This time we were focusing on developing a design pattern for filtering data by time and working out a neat way to show the, sometimes complex, hierarchies in data. Alongside this, we continue to grapple with how to make the complexity of statistical geographies appear in a sensible manner to our users. One of the things we have seen in our user research is a clear need to ensure that geography is constantly grounded in the context a user perceives it (so some people think in terms of towns, others postcodes, others electoral wards and so on).
Alongside this user experience work, the team is looking at building out the react.js components of the project have been considering some of the NFRs we need to factor for and have been building out our automated testing suite.
From a database and API point of view, we have been continuing to iterate a number of API designs. This is turning into an interesting theme. Rapid iterations of API designs now are good, but as the project becomes more mature, further changes start to have a bigger impact. As ever, the world of agile is here to help us with this, but it is a theme that was raised in the end-of-sprint retrospectives. In addition, we have swapped out a relational database for a content store and continued to optimise the graph data base that will hold much of the data. Tests this sprint were run on a dataset containing 33 million observations and this has taught us that the system does work, but we can do more to batch the import process.
We have also been doing a lot of further work to continue to transform our datasets into a consistent format that we are able to process. The transformation pipeline is something that is moving along well within the project, but it is going to be something that we will have to continue to invest time and effort in. The range of data ONS produces is vast and the complexity and interlinking of data can vary massively.
Finally, the dev-ops component continues at pace. The focus here has been around getting the system ready for some serious NFR testing, especially around security. Good progress is being made here and it (the external testing) is some of a small number of external dependencies we have to manage as the project hits full speed.
The team has started to work on Sprint 7 and have some clear priorities to work towards. One is a working environment for all of our services to run on and our automated test suite to run over. We will also continue to develop the first drafts of the core APIs to the point that a working version of the system (from end to end) is possible. This is an exciting time in any project. In addition, our UX team has elected to call a design sprint to allow them to find the time and space to take a look at some of the knottiest challenges we have found in the representations of geography and we will be running a user research session in Bristol.
We are always looking for more people to undertake user research with, so if you are interested in joining in, please do get in contact.
An update on this and more will be here in a couple of weeks.